GPT4D: Generative Pre-training Transformer with Next-Scale Spatio-temporal Token Prediction for 4D Human Action Recognition
Mar 5, 2026·,,,,,·
0 min read
Jiuming Liu*
Haifeng Sun*
Wentao Le*
Mengmeng Liu
Xuyi Hu
Per Ola Kristensson
Abstract
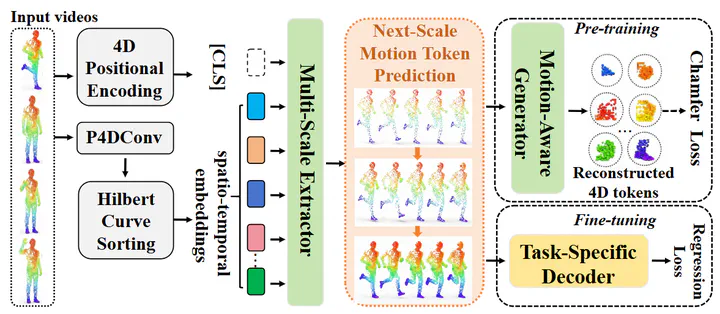
4D human point cloud videos provide a rich representation of human activities by capturing both spatial geometry and temporal dynamics, revealing how people understand and interact with the evolving physical world. However, the inherent irregularity and sparsity of point clouds pose significant challenges in proposing effective 4D backbones. Furthermore, existing supervised methods commonly suffer from labor-intensive 4D annotation costs. To address these challenges, we develop GPT4D, an autoregressive framework that leverages generative pre-training transformers (GPT) to extract 4D spatio-temporal features for human action recognition. Compared to previous self-supervised approaches that resort to complicated contrastive learning or knowledge distillation designs, our method revisits GPT-style pre-training by simply serializing 4D tokens and then reconstructing original sequences through a generative extractor-generator pipeline. To capture multi-granularity dynamics, we also design a Next-Scale Motion Token Prediction strategy that progressively generates more fine-grained spatio-temporal structures from coarser ones. Extensive experiments on 4D human action or gesture recognition datasets, such as MSR-Action3D, SHREC'17, and NvGesture, demonstrate that GPT4D achieves state-of-the-art performance. Code will be released upon publication.
Type
Publication
In submission to ECCV 2026